A inferência vai da amostra à população (Casella and Berger 2002; Bolfarine and Sandoval
1998). Usamos MASS::Pima.tr: dados reais de 200
mulheres da etnia Pima, com medidas clínicas e diagnóstico de
diabetes.
dados <- MASS::Pima.trEstimação pontual por máxima verossimilhança
Dada uma amostra de uma densidade , a verossimilhança e a log-verossimilhança são
e o estimador de máxima verossimilhança é . Para o índice de massa corporal (IMC), supondo Normal:
x <- dados$bmi
ll <- function(th) sum(dnorm(x, th[1], th[2], log = TRUE))
rnp_emv(ll, inicio = c(30, 5), nomes = c("media", "desvio"))$estimativas
#> # A tibble: 2 × 6
#> parametro estimativa erro_padrao z ic_inf ic_sup
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 media 32.3 0.432 74.7 31.5 33.2
#> 2 desvio 6.11 0.306 20.0 5.52 6.71A EMV da média é 32.31. O erro-padrão vem da curvatura de no máximo, medida pela informação de Fisher:
Quanto mais afilada a log-verossimilhança, mais informação os dados trazem e menor a incerteza:
rnp_log_verossimilhanca(function(mu) sum(dnorm(x, mu, sd(x), log = TRUE)),
intervalo = c(31, 35))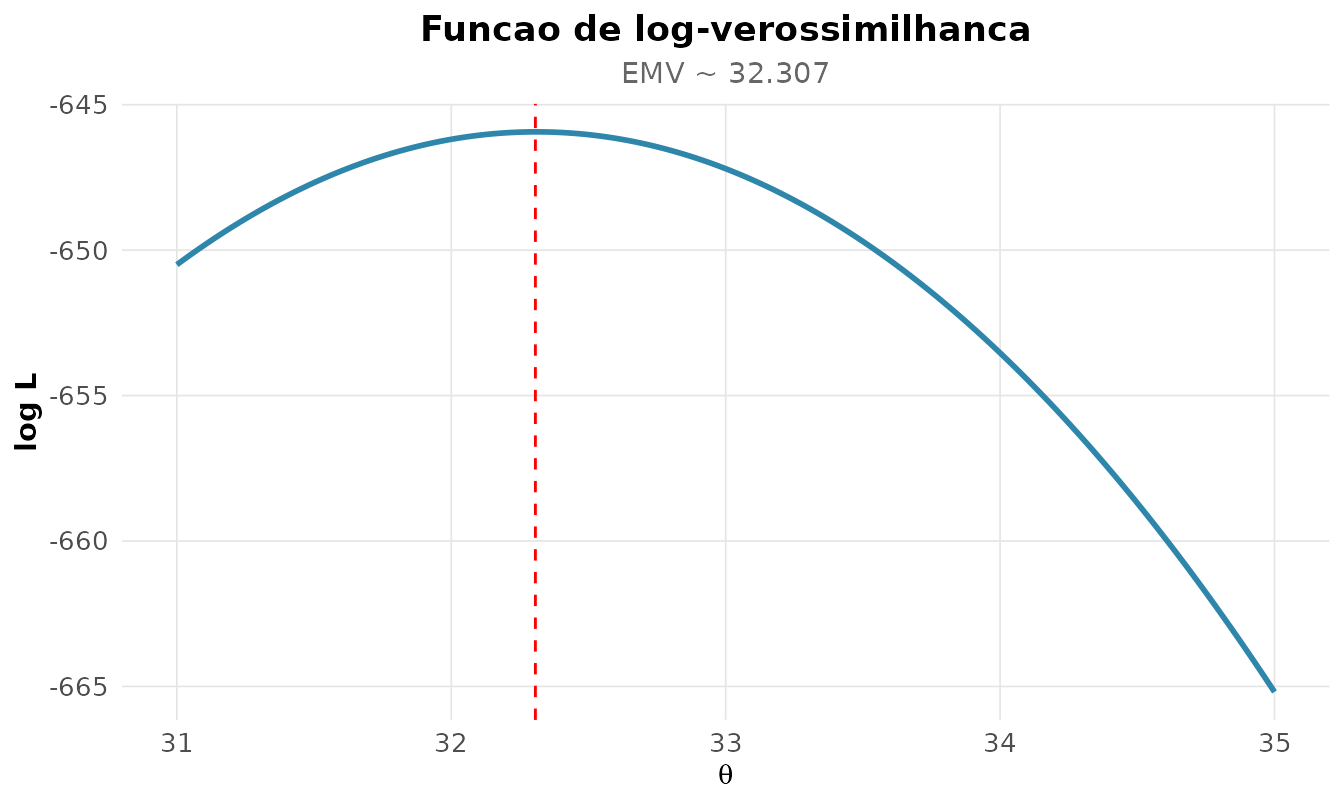
Método dos momentos
Uma alternativa mais simples iguala os momentos amostrais aos teóricos. Para a Normal, ele coincide com a EMV; para outras famílias, fornece um ponto de partida:
rnp_metodo_momentos(dados$bmi, dist = "norm")
#> # A tibble: 2 × 2
#> parametro estimativa
#> <chr> <dbl>
#> 1 media 32.3
#> 2 dp 6.13A EMV costuma ser mais eficiente (menor variância assintótica), mas o método dos momentos é útil quando a verossimilhança é difícil de maximizar.
Intervalo de confiança
Para a média de uma Normal com variância desconhecida, o IC de nível é
rnp_ic_media(dados$bmi)
#> # A tibble: 1 × 7
#> media erro_padrao limite_inferior limite_superior n nivel_confianca
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 32.3 0.434 31.5 33.2 200 0.95
#> # ℹ 1 more variable: distribuicao <chr>O IC de 95% é . A interpretação frequentista correta: se o estudo fosse repetido muitas vezes, 95% dos intervalos assim construídos conteriam a média verdadeira. A confiança está no procedimento, não neste intervalo particular — não é “95% de probabilidade de a média estar aqui”.
Teste de hipóteses e o p-valor
O IMC médio difere de 30 (limiar de obesidade)? A estatística do teste é :
rnp_teste_t(dados$bmi, mu = 30)
#> # A tibble: 1 × 10
#> estatistica gl p_valor media_x media_y diff ic_inf ic_sup hipotese_nula
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 5.33 199 0 32.3 NA 2.31 31.5 33.2 30
#> # ℹ 1 more variable: alternativa <chr>Com e 199 graus de liberdade, : rejeita-se . O p-valor é a probabilidade de observar uma estatística tão ou mais extrema que a obtida, supondo verdadeira. Ele não é a probabilidade de ser verdadeira, nem mede o tamanho do efeito. Toda decisão convive com dois erros: o tipo I (, rejeitar verdadeira) e o tipo II (, não rejeitar falsa).
Poder e tamanho de amostra
O poder é a probabilidade de detectar um efeito real. Quantas observações são necessárias para detectar um efeito médio (d de Cohen ) com 80% de poder, em duas amostras?
rnp_tamanho_amostra_teste(efeito = 0.5, poder = 0.8, tipo = "duas")
#> # A tibble: 1 × 5
#> efeito poder_alvo alpha n poder_obtido
#> <dbl> <dbl> <dbl> <int> <dbl>
#> 1 0.5 0.8 0.05 64 0.802São necessárias 64 observações por grupo. A curva de poder mostra o compromisso entre e a capacidade de detecção:
rnp_poder_teste(efeito = 0.5, n = 30, tipo = "duas")$grafico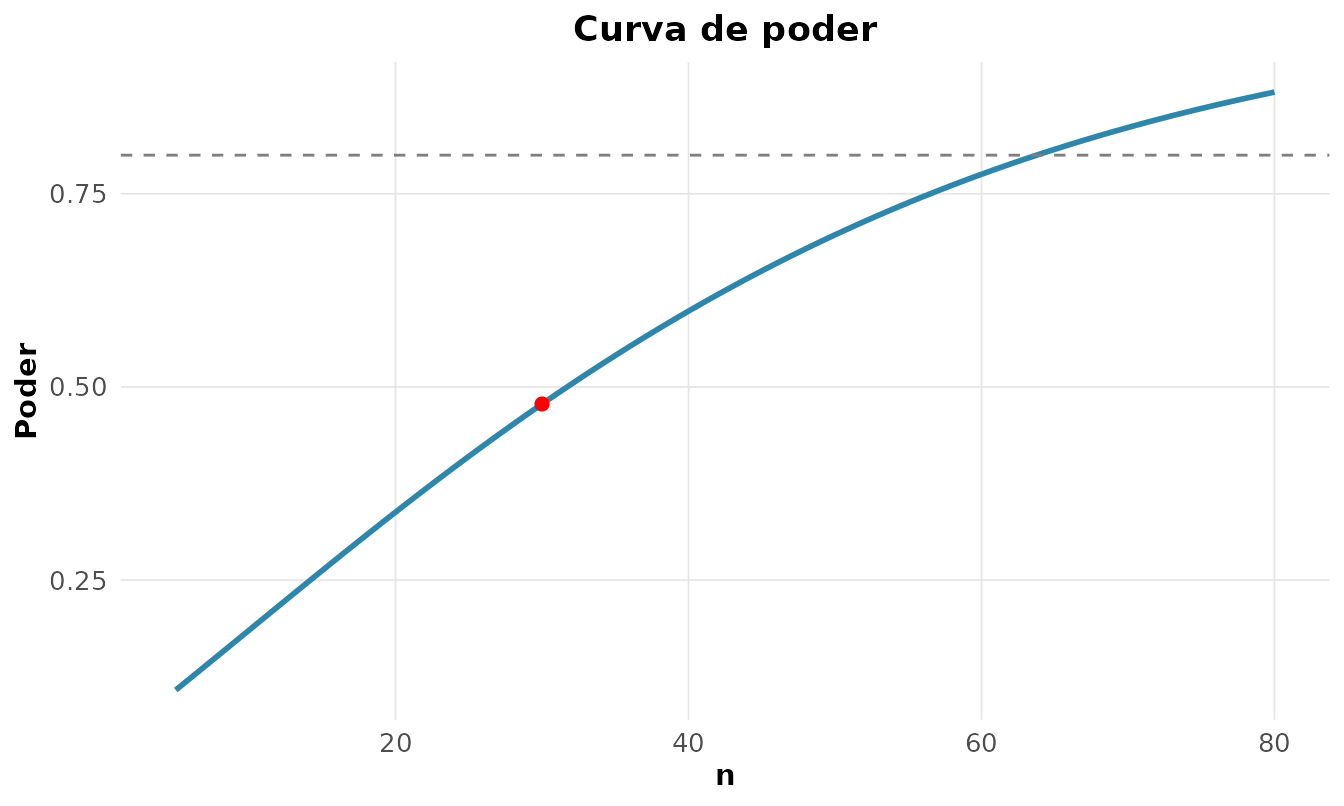
Calcular poder e tamanho de amostra antes da coleta é parte do bom planejamento, e ajuda a evitar tanto falsos negativos quanto achados que não se replicam.
Bootstrap: inferência sem fórmula fechada
Para a média, o erro-padrão tem forma fechada (). Para a mediana, não. O bootstrap (Efron and Tibshirani 1993) reamostra a própria amostra com reposição e observa a variabilidade da estatística:
rnp_ic_bootstrap(dados$bmi, estatistica = "mediana", B = 1000, tipo = "percentil")
#> # A tibble: 1 × 5
#> estimativa limite_inferior limite_superior metodo conf
#> <dbl> <dbl> <dbl> <chr> <dbl>
#> 1 32.8 31.6 33.8 percentil 0.95O IC percentil para a mediana do IMC é , obtido sem qualquer suposição de normalidade.
Comparação de dois grupos
Diabéticas e não-diabéticas diferem na glicose? O teste t para duas amostras (versão de Welch, que não assume variâncias iguais) compara as médias, e o IC para a diferença quantifica a magnitude:
g1 <- dados$glu[dados$type == "Yes"]
g0 <- dados$glu[dados$type == "No"]
rnp_teste_t(g1, g0)
#> # A tibble: 1 × 10
#> estatistica gl p_valor media_x media_y diff ic_inf ic_sup hipotese_nula
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 7.39 122. 0 145. 113. 32.0 23.4 40.5 0
#> # ℹ 1 more variable: alternativa <chr>
rnp_ic_diff_medias(g1, g0)
#> # A tibble: 1 × 6
#> diff_medias erro_padrao limite_inferior limite_superior gl metodo
#> <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
#> 1 32.0 4.33 23.4 40.5 122. t (Welch)A diferença é de 32 mg/dL (145 contra 113), com IC de 95% e : associação forte e claramente significativa.
Teste de permutação
E se a normalidade for duvidosa? O teste de permutação dispensa o TCL, construindo a distribuição nula por reamostragem dos rótulos sob :
rnp_teste_permutacao(g1, g0, B = 2000)
#> # A tibble: 1 × 4
#> diff_observada p_valor B alternativa
#> <dbl> <dbl> <dbl> <chr>
#> 1 32.0 0 2000 bilateralA diferença observada e o p-valor coincidem com os do teste t — quando os pressupostos valem, paramétrico e não-paramétrico concordam, e a concordância reforça a conclusão.
Síntese
| Conceito | O que é | Erro comum |
|---|---|---|
| Verossimilhança | plausibilidade dos dados sob | confundir com probabilidade de |
| IC de 95% | 95% dos intervalos cobririam o parâmetro | “95% de chance de estar aqui” |
| p-valor | ||
| Poder | ignorá-lo no planejamento | |
| Bootstrap | EP por reamostragem | usar só quando há fórmula |
Mais do que calcular cada quantidade, vale entender o que ela significa — e o que não diz.
Exercícios
Resolva com o rnp, usando MASS::Pima.tr,
mtcars, sleep e chickwts.
- Estime, por máxima verossimilhança, os parâmetros de uma Normal
ajustada a
mtcars$mpg(rnp_emv). - Estime os mesmos parâmetros pelo método dos momentos e compare
(
rnp_metodo_momentos). - Calcule a informação de Fisher e o erro-padrão da média do IMC em
MASS::Pima.tr(rnp_informacao_fisher). - Construa o IC de 95% e de 99% para a média de
mtcars$mpg; o de 99% é mais largo? Por quê? (rnp_ic_media). - Teste se a pressão arterial média (
MASS::Pima.tr$bp) difere de 70 (rnp_teste_t). - Compare a média de
mpgentre câmbio manual e automático emmtcars, com teste t de duas amostras (rnp_teste_t). - Construa o IC para a diferença de médias do exercício anterior
(
rnp_ic_diff_medias). - O conjunto
sleepé pareado (mesmos indivíduos). Teste o efeito do medicamento com teste t pareado (rnp_teste_t,pareado = TRUE). - Refaça a comparação de
mpg(manual vs automático) por teste de permutação e compare o p-valor (rnp_teste_permutacao). - Estime o IC bootstrap percentil para a mediana de
mtcars$hp(rnp_ic_bootstrap). - Compare os métodos
percentil,basicoebcapara o IC bootstrap da média demtcars$wt(rnp_ic_bootstrap). - Calcule o IC de 95% para a variância de
mtcars$qsec(rnp_ic_variancia). - Determine o tamanho de amostra para detectar
com poder de 0,80 (
rnp_tamanho_amostra_teste) e trace a curva de poder (rnp_poder_teste). - Teste a normalidade de
chickwts$weightpor três métodos (rnp_teste_normalidade). - Aplique o teste de Wald aos coeficientes de uma regressão logística
(
rnp_teste_wald) e o teste da razão de verossimilhanças entre dois modelos aninhados (rnp_teste_razao_veross). - Atualize uma priori Beta(1,1) com 8 sucessos em 10 ensaios e obtenha
o intervalo de credibilidade (
rnp_bayes_conjugada).